
Encrypted PDFs
I received a bug report for my pdf-parser: it could not decompress the streams of a PDF document (FlateDecode decompress failed).
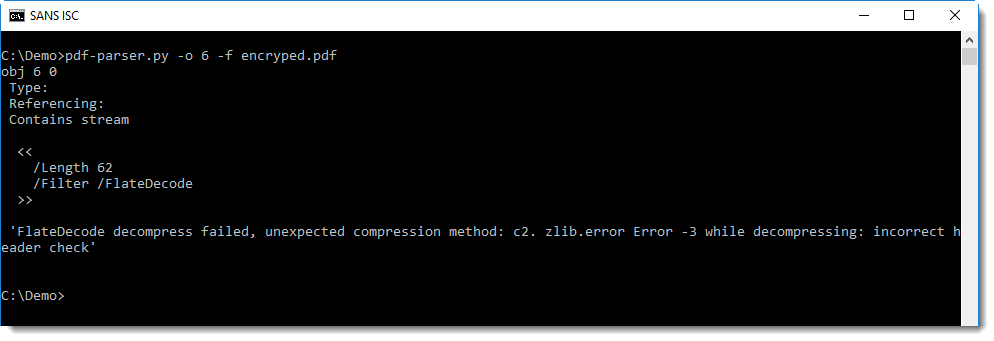
The real reason of the error, is that the PDF document is encrypted, something that is easy to check with pdfid:
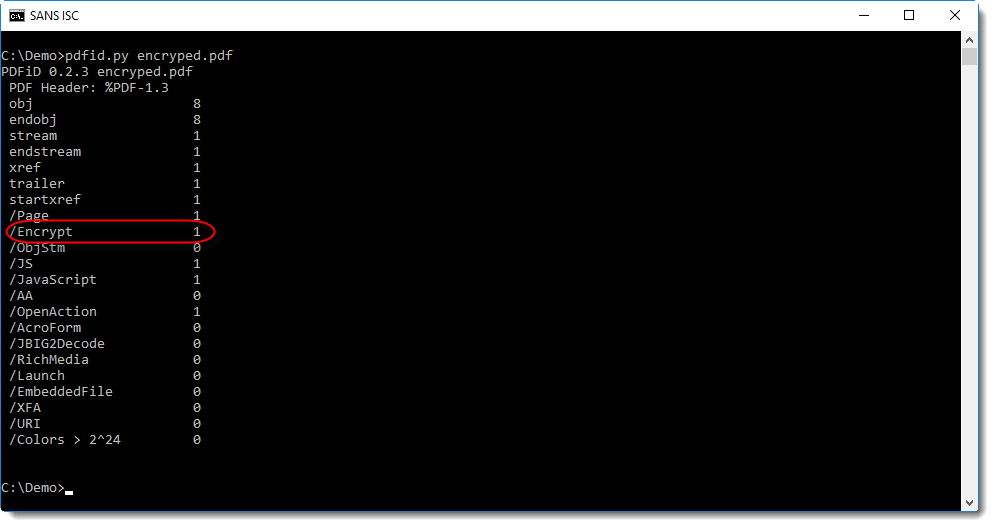
Encypted PDFs retain their structure, what is encrypted is the content of streams and strings.
pdf-parser.py can analyze encrypted PDFs, but it can not look into the content of streams and strings: the PDF must be decrypted first, for example with a tool like QPDF.
PDFs can be encrypted for 2 reasons: for DRM and for confidentiality. PDFs encrypted for DRM can be decrypted without password, while PDFs encrypted for confidentiality require a password (QPDF handles both types).
Sometimes, malware authors will encrypt their malicious PDFs to try to evade detection. If you don't know the password of the malicious PDF you want to analyze, you can try to crack the password.
Didier Stevens
Microsoft MVP Consumer Security
blog.DidierStevens.com DidierStevensLabs.com

Comments