Why use Regular Expressions?
As an IT professional you may already know some Regular Expressions (Regex) and have experimented with tools such as grep to search for a pattern in your log files for a certain piece of text (i.e. actor IP address). Often enough, having to parse huge amount of data usually takes time to get the result but we all realize using Regex can be powerful, by using a few tools (i.e Perl, grep, sed or awk) can take a complex task and turn it into an automated task that is now easy to solve. Working in security, also means to be challenged into parsing or sifting through large amount of data to find the answer that might not always be obvious.
However, you might ask yourself, how do I tackle this problem without having to use complex programs such as moving the data into a database and having to write a frontend that will provide the answer I'm looking for. The answer is either to script or combine the results using well known Unix tools (most of them are available as Windows binaries) into a usable output. Regex can automate such a task(s) that sometimes can take minutes or hours to complete.
It is quite conceivable some of the security tools or devices deployed in your network are using some form of Regex to parse the data it inspects. These could be Snort rules as one example or logs collected by SIEM.
Here are a few examples. I need to retrieve every IP addresses from subnet 192.168.25.0/24 from a logfile. To ease this task, I can use grep:
grep "192\.168\.25\.[[:digit:]]\{1,3\}" query.log
grep -e "192\.168\.25\.\{1,3\}" query.log
Another simple yet powerful search is to completely ignore subnet 192.168.25.0/24 and show everything else. The –v (invert-match) in grep selects non matching lines:
grep -v -e "192\.168\.25\.\{1,3\}" query.log
When required replacing a string of text in one or more documents, one Unix application well suited for this task is sed. This example searches for http: and deletes it every times it finds it in the file. The s is for search (regex) and g is for copy/append.
sed 's/http://g' file.txt > newfile.txt
sed can also be used to delete all empty lines in a file:
sed '/^$/d' file.txt > newfile.txt (The results is sent to newfile.txt and preserves the original)
sed '/^$/d' -i file.txt (Warning: This example removes the empty lines and overwrite the original)
This last example takes the results of one regex and pipes the results to another regex tool or tools. Reusing the above example,
file.txt wc -l (Counts the number of lines in the file before processing)
sed '/^$/d' file.txt | wc -l (Counts the number of lines in the file after processing)
The "The Regex Coach" is a tool that can help ease learning for those who are new to Regex. In the Regular Expression window, you can build your Regex pattern step-by-step and watch the results and the Target string window shows and highlight if you Regex is parsing the data correctly. Here is an example of DNS data where each fields are separated with 2 pipes (IP address 192.168.25.99 is highlighted in both windows):
String: 1374432453.842653||192.168.25.99||64.71.255.198||IN||s0-2mdn-net.l.google.com.||A||74.125.226.156||228||1
Regex: (\d*).(\d*)\|\|(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})\|\|(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})\|\|(\w*)\|\|(.*\.)\|\|(\w{1,3})\|\|(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})\|\|(\d*)\|\|(.*)
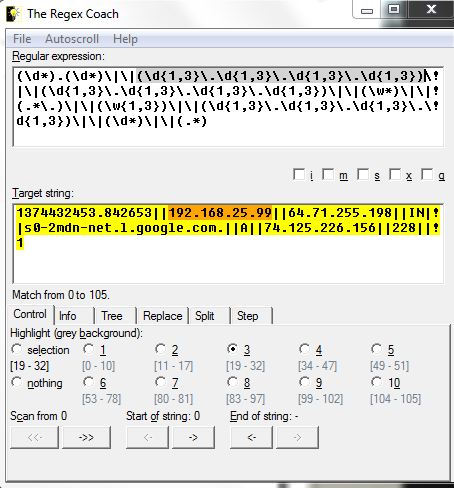
The following regex characters have the following meaning:
\d Match a digit character
\w Match a "word" character
Regex are a powerful way used to search about anything in text based files for data with an identifiable pattern.
[1] http://www.weitz.de/regex-coach/
[2] http://gnuwin32.sourceforge.net/
[3] http://en.wikipedia.org/wiki/Regular_expression
[4] http://www.regexpal.com/
[5] http://regexlib.com/Contributors.aspx
[6] http://regexlib.com/CheatSheet.aspx
-----------
Guy Bruneau IPSS Inc. gbruneau at isc dot sans dot edu
Ubuntu Forums Security Breach
Ubuntu forums are currently down because they have been breached. According to their post, "the attackers have gotten every user's local username, password, and email address from the Ubuntu Forums database." [1] They have advised their users that if they are using the same password with other services, to change their password immediately. Other services such as Ubuntu One, Launchpad and other Ubuntu/Canonical services are not affected. Their current announcement is can be read here.
Update: Ubuntu posted a post mortem on the Forums compromised that occurred last week available here. They provided a good summary on how they think the compromised occurred and what they did to clean and harden the site against further attack.
[1] http://ubuntuforums.org/announce.html
[2] http://blog.canonical.com/2013/07/30/ubuntu-forums-are-back-up-and-a-post-mortem/
-----------
Guy Bruneau IPSS Inc. gbruneau at isc dot sans dot edu

Comments